
好大夫网站医生信息采集解决方案
好大夫网站是中国领先的医疗健康平台之一,提供医生信息、评级、医院信息等内容。为了帮助一家医疗研究机构更好地了解医生的综合情况和患者反馈,我们为该机构提供了针对好大夫网站的医生信息采集解决方案。
解决方案概述:
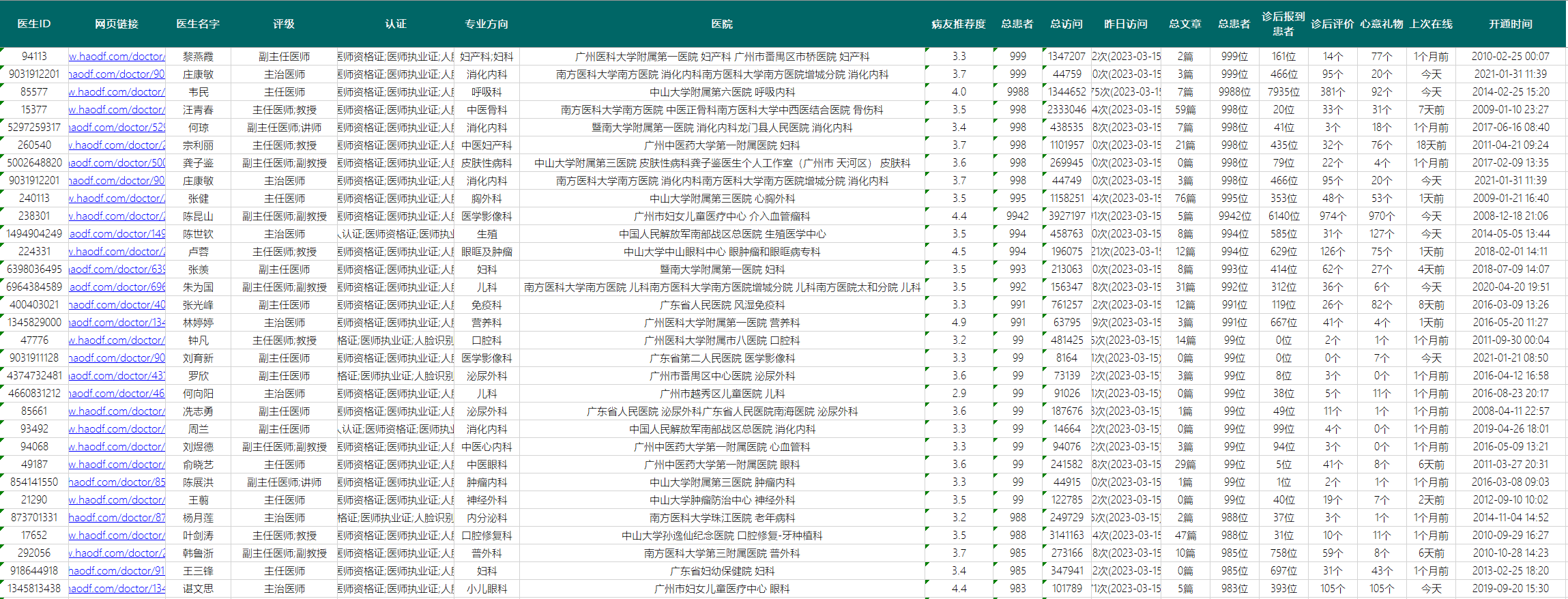
我们的解决方案基于Python编程语言,利用网络爬虫技术实现对好大夫网站医生信息的自动化采集。以下是我们采集的具体字段:
-
医生ID:每位医生在好大夫网站的唯一标识符。
-
网页链接:医生在好大夫网站的个人主页链接。
-
医生名字:医生的姓名或昵称。
-
评级:医生在好大夫网站上的综合评级。
-
认证:指示医生是否通过了好大夫网站的认证流程。
-
专业方向:医生的专业领域或专长。
-
医院:医生所在的医院名称。
-
病友推荐度:患者对医生的推荐程度。
-
总患者:医生的总患者数量。
-
总访问:医生主页的总访问量。
-
昨日访问:医生主页在昨日的访问量。
-
总文章:医生在好大夫网站上发布的总文章数。
-
诊后报到患者:医生的诊后报到患者数量。
-
诊后评价:医生的诊后评价数量。
-
心意礼物:医生收到的心意礼物数量。
-
上次在线:医生在好大夫网站上的上次在线时间。
-
开通时间:医生在好大夫网站上的开通时间。
Python代码示例:
以下是一个简单的Python代码示例,展示如何使用网络爬虫库BeautifulSoup和requests实现对好大夫网站医生信息的采集:
import requests
from bs4 import BeautifulSoup
# 定义目标网页的URL
url = "http://www.haodf.com/doctorteam/list.htm"
# 发送请求获取网页内容
response = requests.get(url)
html_content = response.text
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(html_content, "html.parser")
# 定位医生信息所在的HTML元素
doctor_list = soup.find_all("div", class_="doctor-list-item")
# 遍历医生列表,提取字段信息
for doctor in doctor_list:
doctor_id = doctor.get("id")
doctor_link = doctor.find("a")["href"]
doctor_name = doctor.find("h3").text
rating = doctor.find("span", class_="rating").text
certification = doctor.find("span", class_="certification").text
# 提取其他字段...
# 打印或保存字段信息
print("医生ID:", doctor_id)
print("网页链接:", doctor_link)
print("医生名字:", doctor_name)
print("评级:", rating)
print("认证:", certification)
# 打印或保存其他字段...请注意,在实际应用中,需要根据好大夫网站的网页结构和字段定位进行适当的修改和扩展,以确保准确采集所需的医生信息。
如果您对更多数据采集解决方案感兴趣或有特定需求,我们鼓励您与我们联系。
我们公司专注于提供定制化的数据采集解决方案,可以根据您的具体需求和行业特点,为您量身定制解决方案,以满足您的数据采集和分析需求

添闻,您的数据采集之选,始终如一!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



